4• 3 • Data Justice Frameworks •
 Data justice is about addressing structural problems of oppression and injustices in the world of data, data-driven technologies and systems. Hence, it is important to address data and data-driven technologies as they relate to human needs and the socio-cultural reality of citizens. Asking what people’s needs are, rather than what rights they may claim, makes it possible to think across cultural framings of justice given that rights are not universally shared by all cultures. When thinking about data justice frameworks, it is critical to envision the individual as part of a context with socio-technical and cultural structures that constraint or facilitate his/her agency and conscious actions.
Data justice is about addressing structural problems of oppression and injustices in the world of data, data-driven technologies and systems. Hence, it is important to address data and data-driven technologies as they relate to human needs and the socio-cultural reality of citizens. Asking what people’s needs are, rather than what rights they may claim, makes it possible to think across cultural framings of justice given that rights are not universally shared by all cultures. When thinking about data justice frameworks, it is critical to envision the individual as part of a context with socio-technical and cultural structures that constraint or facilitate his/her agency and conscious actions.
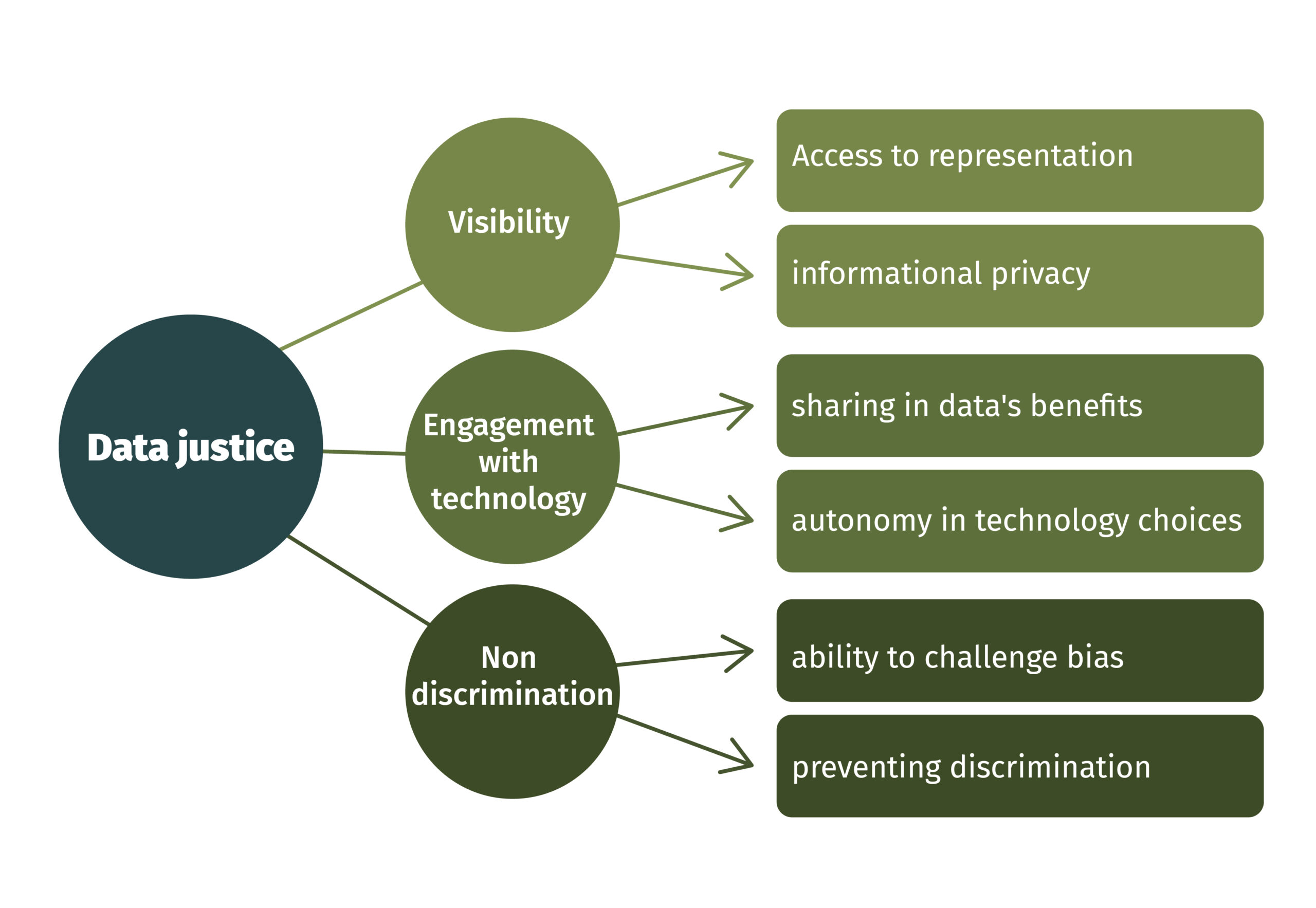
Given the variety of approaches to data justice (e.g. Renken and Heeks, 2016; Floridi; 2014; Dencik, L., Hintz, A., & Cable, J., 2016; Heeks, 2017) we are inspired by the work of Linnet Taylor (2017) who proposes a framework that uses Sen’s Capability Approach to conceptualise data justice along three dimensions of freedoms: (in)visibility, digital (dis)engagement, and nondiscrimination, putting the freedom of the individual to choose the life he/she considers worth living, at the forefront of the framework. That is, choosing to be visible or not and to engage with technology or not. These ideas are the product of current research (if you want to know more, there are different papers that address this topic, which you can find in our recommended Reading list) about what is important to the way people think about data’s potential. Taylor believes that:
We should be visible in ways that benefit us, but also have privacy when visibility is counter to our interests. We should be free to use data technologies in ways that we choose, but should not be used by those technologies. Finally, we should have the ability to challenge discrimination, and should also be guarded from discrimination by those in charge of governing technology development and use.
Using the Capability Approach this framework is aimed to offer a human-centred approach where people’s needs are of high importance. at reconciling negative with positive technologically-enabled freedoms, integrating data privacy, (non)discrimination and non-use of data technologies into the same framework that includes the right to be represented and counted and access to data.
 Issues such as governments hacking data on political opponents, mobile phone records being released without consent but, sometimes also data released with consent initially, that for some reason is later been given a different use, communities unable to access data on how development funds are being spent or the case of Aardhaad in India, require an approach to data justice that pays more attention to agency and practices. It needs to stress more the role of individuals not only as data producers but also, as data users. And as we explained at the beginning, data justice is concerned with structural inequalities and this means that a framework for it needs to pay attention to social structure, for it is this and the power dynamics embedded within it that partially determines issues of maldistribution of data, misrepresentation of minority groups and misrecognition of cultural differences, to name but a few of the current data injustices.
Issues such as governments hacking data on political opponents, mobile phone records being released without consent but, sometimes also data released with consent initially, that for some reason is later been given a different use, communities unable to access data on how development funds are being spent or the case of Aardhaad in India, require an approach to data justice that pays more attention to agency and practices. It needs to stress more the role of individuals not only as data producers but also, as data users. And as we explained at the beginning, data justice is concerned with structural inequalities and this means that a framework for it needs to pay attention to social structure, for it is this and the power dynamics embedded within it that partially determines issues of maldistribution of data, misrepresentation of minority groups and misrecognition of cultural differences, to name but a few of the current data injustices.
We have chosen this framework as it goes beyond the mere application of principles of fairness, transparency and accountability, which whilst being highly salient, is not sufficient for guaranteeing an enactment of justice that is centred around human needs. In addition, the framework serves as the theoretical basis for a European research project: Global Data Justice in an Era of Big Data: Towards an Inclusive Framing of Informational Rights and Freedoms. We consider it has theoretical robustness and can serve the purposes of addressing the structural inequalities that we have identified earlier. The framework is ongoing work that is being refined through public debate.
- The first pillar, visibility, brings to the fore the need for transparency and information privacy. The strands of work include privacy at the social margins (Arora, 2016; Hope & Guilliom, 2003), the risk to group privacy through collective profiling (Taylor, 2016a; Raymond 2016; Floridi 2014) and the extent to which data may be considered a public good (Taylor 2016).
- The second pillar is the freedom not to use particular technologies, and not to become part of commercial databases as a by-product of development interventions. It is related to the ability to control the terms of one’s engagement. Having the power to understand and determine one’s own visibility is part of being able to choose, to have freedoms, which is important for Sen’s idea of development. Currently, the vast majority of individuals are unable to define for themselves how their data are used, to whom they are re-sold or the kinds of profiles and interventions those data can enable.
- The third pillar is discrimination. This implies that methods have to be devised that allow for the governance of algorithmic processes and decision making. Challenging discrimination on the part of individuals will need to be accompanied by the ability to identify and impose sanctions against it on the part of the government (Kroll et al., 2016).
 Data justice for development is thought of as a framework that protects individuals and groups from the social impact of datafication, that is, from being monitored, sorted or classified into particular clusters (e.g. binaries and hierarchies) and then influenced or manipulated through different private and/or public mechanisms (Zuboff, 2019). In line with the focus of data justice on preventing marginalisation and promoting a socially just model for handling data, Taylor’s (2017) approach begins not from a consideration of the average person, but asks instead, what kind of organising principles for justice can address the marginalised and vulnerable to the same extent as everyone else (Taylor, 2017).
Data justice for development is thought of as a framework that protects individuals and groups from the social impact of datafication, that is, from being monitored, sorted or classified into particular clusters (e.g. binaries and hierarchies) and then influenced or manipulated through different private and/or public mechanisms (Zuboff, 2019). In line with the focus of data justice on preventing marginalisation and promoting a socially just model for handling data, Taylor’s (2017) approach begins not from a consideration of the average person, but asks instead, what kind of organising principles for justice can address the marginalised and vulnerable to the same extent as everyone else (Taylor, 2017).
The approach is conceptual and it still needs to be operationalised, which is part of the Global Data Justice in an Era of Big Data project referred to before. It includes both the freedom to use as well as not to use technologies, whilst also addressing the positives and negative sides of data-driven technologies. It proposes to be visible, that is, datafied, but also invisible if one would decide not to be identified, as well as the possibility to engage or not with technology as a right that every individual should have. This, of course, challenges mainstream understanding of data justice and also the current ways in which governance is enacted through surveillance technologies in many parts of the world.
Taylor’s (2017) approach stresses the current tension in three areas: privacy, accountability and responsibility. Given the right social conditions, this view on data justice fosters individual’s agency, so that they can determine their (non)interaction with technology by discussing and if necessary, proposing alternatives. For Taylor and the scholars who are working on this idea of data justice, regaining privacy is paramount, as well as being able to opt-out of being surveilled through one’s data and having the choice not to take part in the production of these data in the first place. The model also implies changes at the governmental level, making governments responsible and accountable for data governance. It proposes accountable data use instead of only responsible data use, which requires structural change. Data governance needs accountability in the way that the food industry already has. When we go to the supermarket and buy food, we are not expert nutritionists, thus we have to rely on the standards that are established to guarantee that it is safe eating what is sold. There is an institution that is accountable for the standards of food (e.g. the milk industry) and whilst we need to have knowledge about nutrition, we generally trust that we are not going to be contaminated. With data governance, something similar needs to happen so that we are protected rather than exploited and potentially harmed.